MySQL 数据库锁定机制
1. MySQL 锁定机制简介
各存储引擎使用三种类型锁定机制
- 行级锁定(row-level)
- 表级锁定(table-level)
- 页级锁定(page-leve) : 页级锁定介于行级锁定与表级锁定之间。
2. MySQL数据库中 表级锁定主要是 MyISAM、Memory、CSV 等一些非事务性存储引擎,使用行级锁定主要是 InnoDB 存储引擎和 NDB Cluster 存储引擎,页级锁定主要是BerkeleyDB存储引擎
3. MyISAM 表级锁定主要分为两种类型
- 读锁定,一个新客户端在申请获取读锁定资源的时候,需要满足两个条件:
- 请求锁定的资源当前没有被写锁定
- 写锁定等待队列 (Pending write-lock queue)中没有更高优先级的写锁定在等待
- (只影响写操作)
- 写锁定
- (影响读操作,同时也影响写操作)
4. MySQL中主要分4中队列来维护这两种锁定:两个存放当前正在锁定的读和写锁定信息,另外两个存放等待中的读写锁定西信息,如下:
- Current read-lock queue ( lock->read)
- Pending read-lock queue (lock->read_wait)
- Current write-lock queue (lock->write)
- Pending write-lock queue (lock->write_wait)
5. InnoDB 的行级锁定分为四种类型
- 共享锁 (有叫做:读锁)
- 允许一个事务去读一行,阻止其他事务获得相同数据的排它锁。
- 排他锁 (有叫做:写锁)
- 允许获得排它锁的事务更新数据,阻止其他事务
- 意向共享锁
- 意向排他锁
6. InnoDB 间隙锁
InnoDB 的锁定是通过在指向数据记录的第一个索引键之前和最后一个索引键之后的空域空间标记锁定信息实现的。这种锁定方式被称为 “NEXT-KEY locking“(间隙锁)
间隙锁弱点:锁定一个范围之后,即使某些不存在的键值也会被无辜锁定,造成锁定的时候无法插入键值锁定内的任何数据。
通过索引实现锁定的方式存在其他几个较大的性能隐患:
- 当 Query 无法利用索引的时候,InnoDB 会放弃使用 行级锁定 而改用 表级锁定 ,造成并发性能降低;
- 当 Query 使用的索引并不包含所有过滤条件时,数据检索使用到的索引键中的数据可能有部分不属于 Query 的结果集行列,但是也会被锁定,因为间隙锁锁定的是一个范围,而不是具体的索引键。
- 当 Query 在使用索引定位数据的时候,如果使用的索引键一样但访问的数据行不同 (索引只是过滤条件的一部分), 他们一样会被锁定。
7. MyISAM 表锁优化建议
- 缩短锁定时间
- 尽量减少大的复杂 Query,将复杂 Query 拆分成几个小的 Query 执行。
- 尽可能地建立足够高效的索引,让数据检索更迅速。
- 尽量让MyISAM 存储引擎的表只存放必要的信息,控制字段类型。
- 利用合适的机会优化 MyISAM 表数据文件。
- 分离能并行的操作
- MyISAM 并非只能完全的串行化,MyISAM 存储引擎还有一个特性 Concurrent Insert(并发插入)的特性。
- MyISAM 存储引擎有一个控制是否打开 Concurrent insert 功能的参数选项: concurrent_insert 可以设置为 0/1/2:具体如下:
- concurrent_insert = 2,无论 MyISAM 存储引擎的表数据文件的中间部分是否存在因为删除数据而留下的空闲空间,都允许在数据文件尾部进行Concurrent Insert。
- concurrent_insert = 1,MyISAM 存储引擎表数据文件中间不存在空闲空间的时候,可以从文件尾部进行 Concurrent Insert。
- concurrent_insert = 0, 无论 MyISAM 存储引擎的表数据文件的中间部分是否存在因为删除数据而留下的空闲空间,都不允许 Concurrent Insert。(读锁时,不允许插入)
- 合理利用读写优先级
- 表级锁定 默认情况下写优先级大于读,如果读操作多的时候,可以设置读优先级高,可设置参数 low_priority_updates = 1。
8. InnoDB 行锁优化建议
- 尽可能让所有的数据检索都通过索引来完成,从而避免 InnoDB 因为无法通过索引键加锁而升级为表级锁定
- 合理设计索引,让 InnoDB 在索引键上加锁的时候尽可能准确,尽可能地缩小锁定范围,避免造成不必要的锁定而影响其他 Query 的执行。
- 尽可能减少基于范围的数据检索过滤条件,避免因间隙锁带来的负面影响而锁定了不该锁定的记录。
- 尽量控制事务大小,减少锁定的资源量和锁定的时间长度。
- 在业务环境允许的情况下,尽量使用较低级别的事务隔离,减少 MySQL 因为实现事务隔离级别所带来的附加成本。
9. 系统锁定争用情况查询
MySQL 内部有两组专用的状态变量记录系统内部资源争用情况。
- 表级锁定的争用状态变量
mysql> show status like ‘table%’;
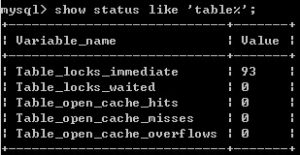
-
- Table_locks_immediate:产生表级锁定的次数;
- Table_locks_waited:出现表级锁定争用而发生等待的次数
Table_locks_immediate 值大于 Table_locks_waited 5000 是比较合适的,在大就需要分析问题所在。
两个状态值都是从系统启动后开始记录,每出现一次加1,如果这里 Table_locks_waited 状态值比较高,说明表级锁定争用严重,需进一步分析。
- InnoDB 行级锁定状态变量记录
sql> show status like ‘innodb_row_lock%’;
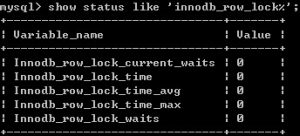
-
- Innodb_row_lock_current_waites:当前正在等待锁定的数量;
- Innodb_row_lock_time:从系统启动到现在锁定总时间长度;
- Innodb_row_lock_time_avg:每次等待所花平均时间;
- Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间;
- Innodb_row_lock_waits:从系统启动到现在总等待次数。
5个状态,比较重要的是 Innodb_row_lock_time_avg(等待平均时长),Innodb_row_lock_waits(等待总次数)及 Innodb_row_lock_time(等待总时长)
10. InnoDB 除了提供以上5个系统状态变量外,还提供了更为丰富的即时状态信息,实现方法如下:
- 创建 InnoDB Monitor 表来打开 InnoDB的 monitor 功能
- mysql > create table innodb_monitor(a int) engine=innodb;
- 然后执行 ”show innodb status” 查看详细信息
为什么创建 innodb_monitor 表?
创建该表就是告诉InnoDB 我们要开始监控他的详细信息,然后InnoDB就会将比较详细的事务级锁定信息记录到MySQL的 error log 中,以便后面做进一步分析。
One thought on “MySQL 数据库锁定机制”
我们好像在哪见过,你知……道吗?
?有千变万化,?有悲喜交加,?有,,,麻蛋 锁的类型太多了!
总之,用合适的工具,合理的方式 干正确的事儿!